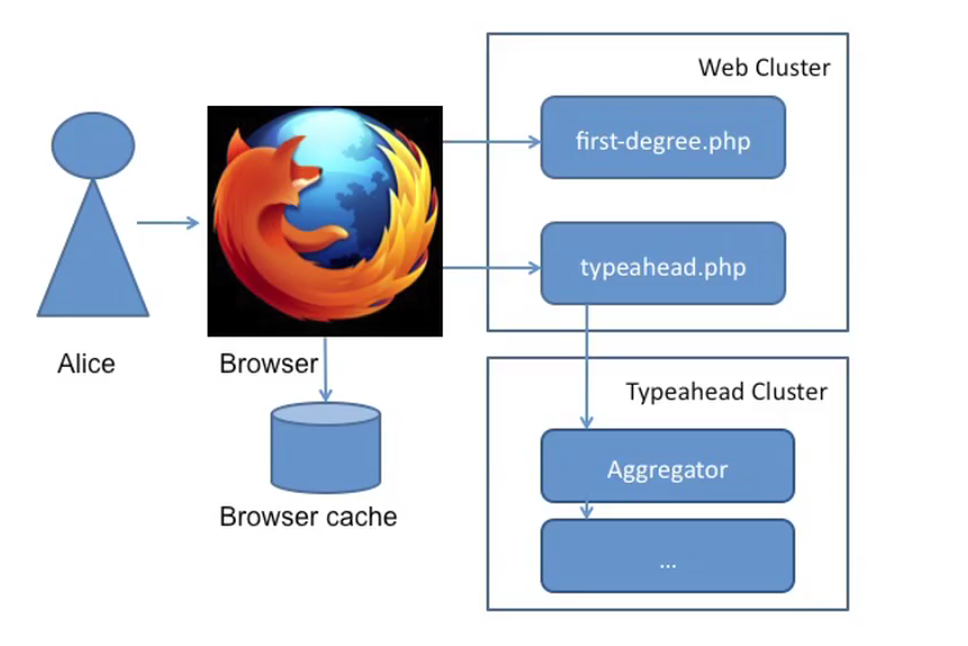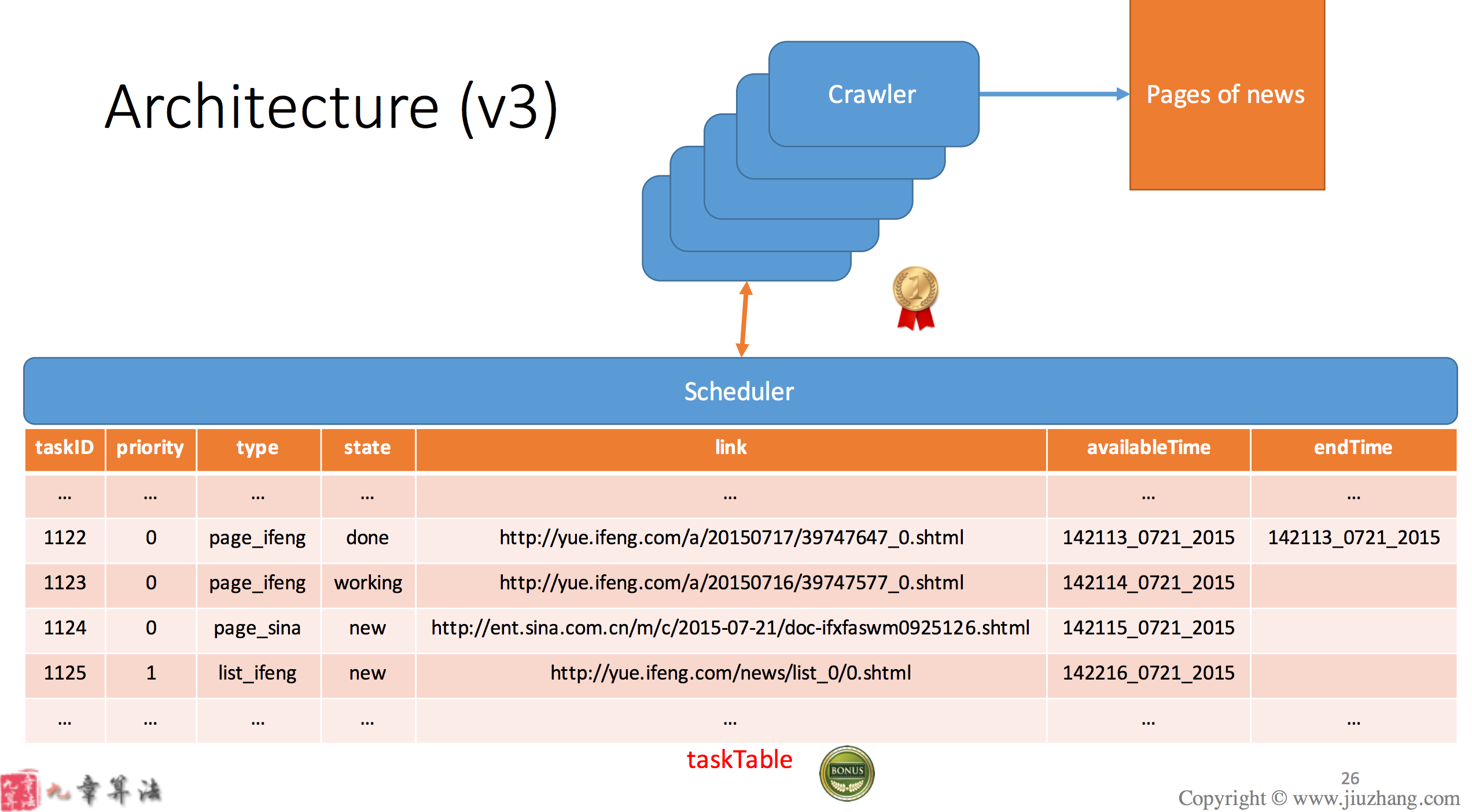
Here we have multiple crawlers which infinitely checking if the task table has any task with status=new, if so we take one task then crawl the page. If the page is a list of the links to other page, we create a task for each link and save to task table. If the page is a real news page, we save it to page table. Eventually we read all the real pages from the page table.
1. Use sleep()
What we can do is if while check if there is any new task in the table, if not, we make the thread sleep for a certain time.
void crawler() {
while (true) {
//before reading, needs to lock the table
lock(taskTable);//*
//check if there is any new task in task table
if (taskTable.find(state == 'new') == null) {
//give up the lock if there is nothing to consume
release(taskTable);//*
sleep(1000);//*
} else {
task = taskTable.findOne(status == 'new');
task.state = 'working';
//release the lock;
release(taskTable);
//crawl by the task url
page = crawl(task.url);
//if page.type is a page including a list of links to the news
if (task.type == 'list') {
lock(taskTable);
for (Task newTask : page) {
taskTable.add(newTask);
}
task.state = 'done';//*
release(taskTable);
}
//if page.type is a news page,
//add to page table
else {
lock(pageTable);
pageTable.add(page);
release(pageTable);
//we still need to update the task by setting the status to be "done"
lock(taskTable);
task.state = 'done';//*
release(taskTable);
}
}
}
}
So the problem using sleep is:
1. 在每次轮询时,如果t1休眠的时间比较短,会导致cpu浪费很厉害;
2. 如果t1休眠的时间比较长,又会导致应用逻辑处理不够及时,致使应用程序性能下降。
2. Conditional Variable
我们利用条件变量(Condition Variable)来阻塞等待一个条件,或者唤醒等待这个条件的线程。
一个Condition Variable总是和一个Mutex搭配使用的。一个线程可以调用cond_wait()在一个Condition Variable上阻塞等待,这个函数做以下三步操作:
1. 释放Mutex
2. 阻塞等待
3. 当被唤醒时,重新获得Mutex并返回
注意:3个操作是原子性的操作,之所以一开始要释放Mutex,是因为需要让其他线程进入临界区去更改条件,或者也有其他线程需要进入临界区等待条件。
In this case, we put all the waiting crawler thread into cond.waitList if there is any.
cond_wait(cond, mutex):
cond_wait(cond, mutex) {
lock(cond.waitList);
cond.waitList.add(Thread.this);
release(cond.waitList);
release(mutex);
sleep();
lock(mutex);
}
How to use cond_wait()?
lock(mutex);
while (!condition) {
cond_wait(cond, mutex);
}
change the condition
unlock(mutex);
cond_signal(mutex):
cond_signal(cond) {
lock(cond);
if (cond.waitList.size() > 0) {
thread = cond.waitList.pop();
}
wakeup(thread);
release(cond);
}
How to use cond_signal(mutex)?
lock(mutex); set condition = true; cond_signal(cond); unlock(mutex);
So the crawler will become:
void crawler(){
while(true){
lock(taskTable);
//it has to be while instead of if
while(taskTable.find(state=='new')==null){
cond_wait(cond, taskTable);//*
}
task = taskTable.findOne(state == 'new');
task.state = 'working';
release(taskTable);//*
page = crawl(task.url);
if(task.type=='list'){
lock(taskTable);
for(Task newTask:page){
taskTable.add(newTask);
cond_signal(cond); //*
}
task.state = 'done';
release(taskTable);
}else{
lock(pageTable);
pageTable.add(page);
unlock(pageTable);
lock(taskTable);
task.state = 'done';
unlock(taskTable);
}
}
}
3. Semaphore
信号量一般是对整数资源进行锁。可以认为是一种特殊的条件变量。
wait(semaphore):
this means if semaphore is larger than 0, if not, it starts waiting until both happens:
1. semaphore.value>=0
2. someone wakes it up
wait(semaphore){
lock(semaphore);
semaphore.value--;
while(semaphore.value<0){
semaphore.processWaitList.add(this.process);
release(semaphore);
block(this.process);
lock(semaphore);
}
}
signal(semaphore):
signal(semaphore){
lock(semaphore);
semaphore.value++;
if(semaphore.processWaitList.size()>0){
process = semaphore.processWaitList.pop();
wakeup(process);
}
release(semaphore);
}
So the crawler now becomes:
while(true){
//we are not querying taskTable here so no need to lock taskTable
wait(numOfNewTasks); //*
lock(taskTable);
task = taskTable.findOne(state =='new');
task.state = 'working';
release(taskTable);
page = crawl(task.url);
if(task.type == 'list'){
lock(taskTable);
for(Task newTask : page){
taskTable.add(newTask);
signal(numberOfNewTask); //*
}
task.state = 'done';
release(taskTable);
}else{
lock(pageTable);
pageTable.add(page);
release(pageTable);
lock(taskTable);
task.state = 'done';
release(taskTable);
}
}
Ref: jiuzhang.com